Legion Thoughts
[Blaugust Day 7]
And the award for easiest Blaugust prompt goes to… WoW’s next expansion, Legion.
Rather than talk about the entire expansion concept as a whole, I wanted to talk about two things that, admittedly, we don’t have enough information about to make informed opinions on.
The first is Artifacts:

Unintentional spoiler about Magni, Blizzard?
There are a whole lot of incidental questions regarding the introduction of Artifacts. Like… 36 of them, really? Also, does this not strongly imply that there is a rather sweeping, Game of Thrones-esque purge of all these weapons’ prior owners? I’m almost imagining a reverse Warlords scenario in which all the story heroes land on the beach, a portal opens up, and the hand of Sargeras comes flying out and grabs them all. Certainly there’s no other explanation possible for why every level 100 paladin will be running around the Ashbringer out of the gate.
This brings me to my primary concern: will there be other weapons this expansion? I can see Blizzard simply not releasing any weapons, as why would you ever not use your spec Artifact? Even if the event that leads us to looting Ashbringer from Tirion’s cold, dead hands renders the weapon “drained of power” or whatever, it’s hard to imagine it feeling good to carry an Artifact around in your back pocket while you equip the first green drop from the second Felboar you kill.
Plus, it makes no sense to introduce a pseudo talent tree in a weapon you won’t be using 24/7:
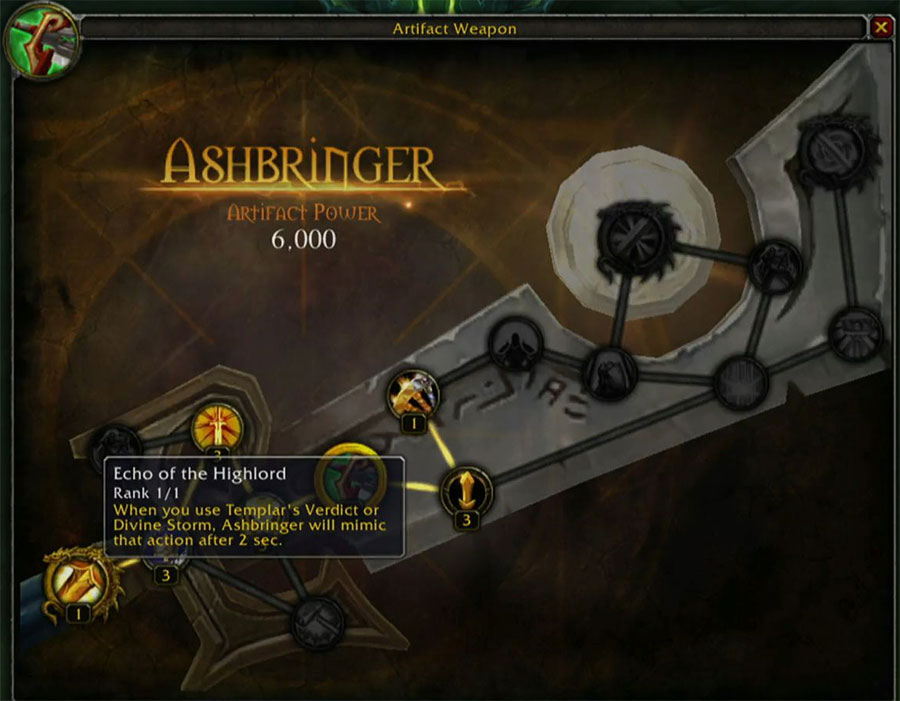
Path of Titans 2.0
So here’s my wild speculation: you’ll be using your Artifact all the time, and Artifact Power is the new Valor points. There is a chance that perhaps we’ll be able to disenchant gear into Artifact Power, thus preserving normal gear progression, but I find it difficult to believe that such a system won’t be gamed hardcore. Having raid bosses drop epic weapons whose sole purpose is to be turned into Artifact points sounds really dumb.
Which, of course, means there’s a 50/50 chance that actually happens.
My second concern is the new direction they are taking WoW PvP. Because unless I’m mistaken, it sounds like they’re removing PvP gear entirely.
You can watch the section yourself starting at 3:52:14 in the Youtube video.
We really want to dial back the effect that gear has. […] It’s just not that fun to have players running around with that huge level of power disparity. So we felt like we needed a new system that addresses that, so that while gear plays a role, it plays almost no role in terms of how powerful you are. […] Essentially what [Honor v3] is, is a PvP talent system.
That sort of quote, along with the description of how Honor v2 was basically a currency-based system “that introduced PvP gear,” leads me to believe that we may see PvP gear just go away. Which… is not the worst scenario ever. I’m not sure how popular Guild Wars 2 BGs are, but they feature vendors that hand out unlimited amounts of free PvP gear to level the playing field. The whole Prestige system also sounds fine, but I don’t know how motivating it will be in practice.
The core gameplay loop in WoW is gear progression. That’s basically it. Even if you “don’t care” about gear, the only reason people grind through raids more than once or twice total is precisely because there is a reason to, e.g. to get better equipped to make the next raid less difficult. PvP is absolutely no fun when you’re sitting in starter gear with 1/3rd less HP than the guy about to ruin your day, yes. It is also absolutely true that the participation pittance you receive after being facerolled in a BG makes said BG worth getting facerolled in. Maybe there are people out there sitting on the Honor cap and raring to go into another Isle of Conquest loss. For me personally though, the moment I reach that gear plateau is the same moment I find more constructive uses of my gaming time.
It’s possible that there will still be PvP gear to be earned despite the direction things are leaning. I’m not entirely sure how that would work if Honor is no longer a currency, but the alternative is Blizzard pushing PvP players back into “raid or die” scenarios. What else would PvPers wear? Or maybe Blizzard would go full GW2 and have vendors standing around. No matter the outcome, it is quite the sea change in Legion.
By the way, this PvP slide raised my eyebrow:
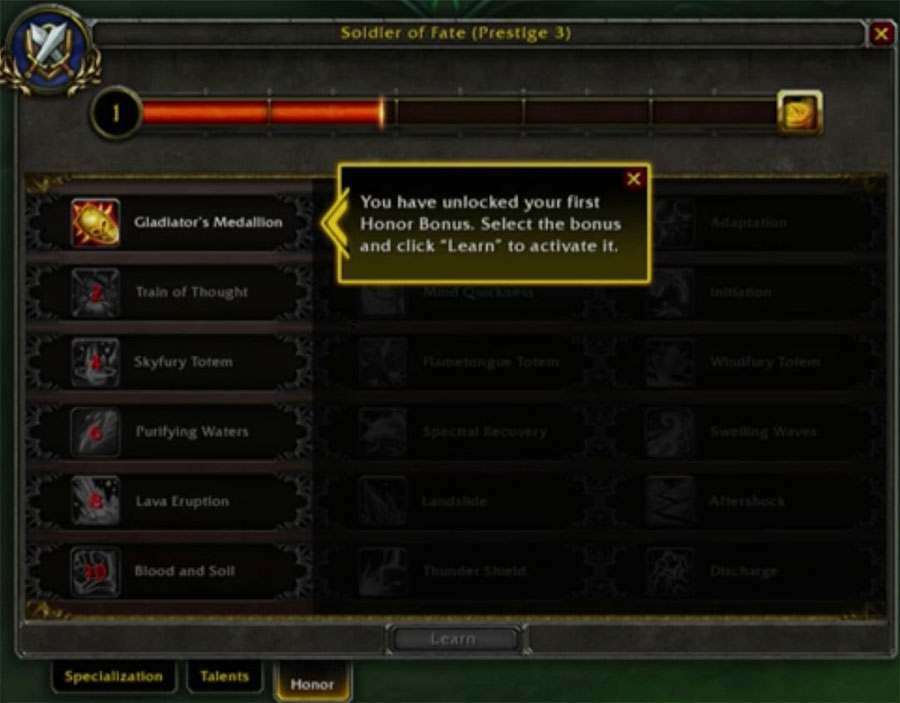
Every Race for Themselves.
For those that may not know immediately, Gladiator’s Medallion is the namesake trinket, i.e. what you press to get out of stuns, etc. So unless the description of the baseline PvP talent is something incredibly clunky like “your trinket’s cooldown is reduced by 30 seconds” or something, I must assume that everyone is getting a PvP trinket baseline. In which case, we’re either going to see the Human racial be completely redesigned again, or… maybe we’ll see the end of racials in PvP altogether. Hell, in the latter scenario, Humans could keep their trinket racial since the PvP talents are only activated in BGs and Arena.
Undoubtedly we’ll be getting more information soon.
Posted on August 7, 2015, in WoW and tagged Artifact, Blaugust, Expansion, Legion, Progression, PvP. Bookmark the permalink. 5 Comments.

I know a lot of the devs are fans of Destiny, and the Artifact weapon upgrade system is almost straight lifted from that.
LikeLike
According to this interview: http://www.icy-veins.com/forums/topic/13199-wow-legion-details-at-gamescom-interview-with-tom-chilton-ion-hazzikostas/, there won’t be other weapon drops during the expansion.
So yes, you’ll be using that weapon 24/7, but I don’t see why the existing enchantment systems would need to change. There’s still the rest of the gear for that, isn’t it? (Actually not too sure about this, since I haven’t played WoW since early Cataclysm).
FFXIV also has a set of iconic weapons, one for each class, that you can upgrade throughout the whole expansion, but they are a long, optional grind and not nearly as customizable as WoWL’s seem to be.
LikeLike
I should point out that they’ve confirmed that the Artifacts can be transmogged so I suspect plenty of people will turn their Ashbringer into something else.
They also said that the stats (like DPS) on artifacts will be supplied by “relics” which sound a lot like the gear from SWTOR where you stick in components. So instead of a new sword dropping, you’ll get a relic that has better DPS.
As for PvP gear, it sounds like in PvP all gear will be normalized. So even if you’re raiding Mythic, you’re gear is the same as the guy who just started today. All that separates people is their honor, and with prestige offering cosmetic rewards there should be a reasonable number of people that aren’t always maxed. I’d imagine a vendor will sell you some “starter” gear and you can get better appearances every time you prestige.
As for “It is also absolutely true that the participation pittance you receive after being facerolled in a BG makes said BG worth getting facerolled in.” I disagree. I appreciate the pittance, but it doesn’t make it any more fun or worthwhile. I’d rather get nothing but be assured good BG matchups than BGs full of AFKers and a pittance.
LikeLike
Unfortunately, the BG choice is “get facerolled and get some Honor” or “get facerolled for nothing.” It could be that normalized PvP gear empties the queues of botters and AFKers and even those people who aren’t that skilled but feel compelled to queue for the rewards (and progression). But it could also be that all the skilled people are still on the other faction and you just get rolled for days for essentially no reason.
LikeLike
Pingback: Legion PvP Equality | In An Age