Category Archives: Miscellany
Discoverability
I think about the tragedy of discoverability a lot.
Maybe “tragedy” is not the right word, but stick with me for a moment. Think about your absolute favorite song, or movie, or game, or book. Was encountering that now-favorite thing inevitable? For some things, maybe the answer is Yes. If you had a Super Nintendo in the 90s, odds are pretty high that you were aware of Final Fantasy 3 (6) or Super Metroid or other bangers that were pre-internet famous even in their day. Then again, perhaps that was a bias I had from reading gaming magazines like Nintendo Power or Game Pro back then. And, of course, it presupposes you (or your parents) had the cash to purchase it for you.
When looking at my music collection though, almost all of my favorite songs were never in any way inevitable. Fifteen years ago, I was working an extremely boring data entry job that nevertheless allowed us to listen to music. I had the entire internet at my disposal, and yet you don’t know what you don’t know. Where does one listen to music, that isn’t just the same 17 songs on the radio? My solution was these monthly indie rock playlist drops, such as BIRP, where you can download like a hundred separate songs, and then winnow them down to the usually 2-3 that were my style. From there, I would download that musician’s discography and then winnow that down, finding more diamonds in the rough. Rinse and repeat.
If I did not have that job, or did not discover the indie rock playlist – which I honestly have no recollection of where I would have encountered it – then some of my favorite songs would just… not exist, from my perspective. Yes, I would still have had my prior favorite song that I did encounter, so in a way it’s relative. In a more concrete way though, it’s very much not relative because my new favorite had greater depths and more fulfilling pathos than what came before.
My job has changed quite a bit over the years, and I no longer felt it was a good use of my time sorting through a hundred songs of what felt like UK punk rock for a single good song. So, I stopped around 2018, it looks like. How many diamonds have slipped through my fingers in the last eight years? Maybe fewer than I think, given I have leveraged more Youtube algorithms for exposure to new stuff. Then again, just like with AI generally, it’s exceedingly proficient at giving you more of what you like, rather than something totally different that you might like more.
I do not know if there is a solution out there for discoverability, other than just putting yourself out there. The corporate machines of the world are certainly spending billions of dollars in trying to put your eyeballs on their products, but for the average piece of content, it’s likely random happenstance at best. And that’s really too bad.
In unrelated news, I’ve signed up for Blaugust again this year, and threw my hat in over at Warp Point.
Time Deletion
Guys… I’m up to 77 hours in Mewgenics. It hasn’t even been two full weeks yet.
That’s not even the worst/best part: Slay the Spire 2 is hitting Early Access on March 5th. It has one of the best trailers I’ve ever seen for a roguelike deckbuilder:
Granted, I don’t really know of many other roguelike deckbuilding trailers.
In any case, yeah, pour one out for my gaming backlog. And frontlog, for that matter. I certainly haven’t been spending any time thinking about Expedition 33 (etc) in the last two weeks. Too busy drinking from the firehose. Perhaps I can circle back in April… no, let’s say May. End of Q2, for sure.
(Heh, I didn’t say of which year)
First Impressions: Clair Obscur: Expedition 33
My first play session with Clair Obscur: Expedition 33 lasted about two hours, and I got through the tutorial and far enough to see the first few real battles. And then I didn’t boot the game back up for almost three weeks.
By the end of the second session… yeah, I can start to see why this is winning all of the awards.

First, the game is trippy and evocative as fuck. The principle bad guy is a goliath-esque woman named The Paintress, which is apt as every environment looks like it sprung directly from some artwork in the Louvre and/or a fever dream. The protagonists live on some kind of island protected by shields or something – with the world itself seeming to have been shattered by some older cataclysm – but the Paintress controls a countdown timer that nevertheless kills everyone older than a specific number. At game start it was 34, and now it’s the eponymous 33. It seems to increment on a yearly basis, but I’m not sure if that was specified (or matters). In any case, every year a small number of adventurers next in line to be erased gets together and attempts to bring the fight to the Paintress. Enter you.
Second, I do want to highly praise the motion-capture and general dialog thus far. It’s passionate, awkward, and deeply human in ways very few other games have been able to reproduce. Nearly 14 years ago, I was blown away by Mass Effect’s wink, and here in Expedition 33 I just witnessed a character search another’s eyes to see if they truly meant what they said. You know, her face close, the silence, her eyes going back and forth with purpose, debriding the layers of your soul. I don’t know how, but they captured it. The bar has been raised again.

We will have to see how it works out for me over the long haul, but my first impression of Expedition 33’s combat system… is that it’s not fun. Basically, it feels like a turn-based Soulslike. Everything more complex than a basic attack will have a Quick-Time Event sequence in order to juice the skill further. On the enemy’s turn, you are essentially required to either Dodge or Parry their attacks; Dodging has a more forgiving window than Parry, but successfully Parrying every attack will allow the party member to unleash a devastating counter-attack. I say Dodging/Parrying is “required” because the amount of damage you end up taking is significant, and your ability to heal is limited and only refreshed when you arrive at checkpoint flags, e.g. campfires. And yeah, enemies respawn when you rest.
What results is a truly conflicting game thus far. I encountered some enemies in the opening areas that were clearly higher-level than my ability to meaningfully tackle. “The designers just wanted to teach me that not every enemy needs fought, and/or that I may want to revisit places once I gained more levels.” OK, great, very Soulslike of you. Buuuuut, technically, if you just Parry all their attacks, you will defeat them eventually. Which then gets you thinking about why bother putting points in Defense or Vitality, when both are irrelevant if you don’t get hit in the first place. Is that the intentional design? Stack Defense if you aren’t good at the timing, and everyone else go glass cannon?

Again, this is all very early on, so perhaps things will improve. Somehow. Or perhaps the combat system is just something you put up with for the environments, dialog, and plot. That is a very old-school RPG sentiment for 2026, but I’m going to roll with it for now.
Vacation
I’ve been on one. Posts to resume next week.
That said, I’ve also been (re?)reading the Expanse series while I’ve been here. Hard to tell if I’ve already read a few before, or if the TV series was just so accurate that it may as well have been a transcript. In which case… doesn’t the TV version just win by default?
Oh, yeah… Blaugust!
That’s certainly a thing I signed up for! Probably should have had a post ready to go or something.
As it turns out, I have been playing Abiotic Factor pretty much nonstop since the 1.0 release. It is not often that I manage to find a game that takes over my entire life, although the survival crafting genre is certainly good for that. I’ll have more to say about the game later, as I’m in that enviable state of not wanting to spend time talking about how much fun I’m having when I could be, well, having fun.
In any case, if you’re a Blaugust tourist, welcome! I’ve been blogging since 2010 with close to 1600 posts full of premium quality words. You can either take my word for it, click on The Goods drop-down over to the right there (I recommend Philosophy) to check for yourself, or, well, buckle up, buttercup.
…for tomorrow. Oh, wait, it’s the weekend. Monday, probably!
Thought Process: OG Switch
Woot currently has a deal up for a brand new OLED Switch for $250. The sale is going until June 18th, or until they sell out, the latter of which seems more likely. Should I pull the trigger?
First question: why?
It’s a good question. For one thing, the Switch 2 just came out and it costs “only” $450. Right now, there aren’t very many actual Switch 2 games beyond Mario Kart World, so no real killer apps. Also, I have clearly sat out the entirety of the Switch’s original lifespan, so why jump in now? Also also, the Switch Lite appears to retail for around $180ish, which is even less, if it were somehow super important for me to play Switch games. Then again, $70 is probably reasonably enough to justify an OLED upgrade plus being able to dock it to a TV.
Not for nothing, the Retroid Pocket 5 can be bought from Amazon for $260. It would be even cheaper if not for the tariffs. It can emulate everything up through Gamecube, and even a few Switch titles. However, the process by which one acquires emulation-ready Switch games is the same for just playing them on the PC, so the only real benefit of one over the other is for gaming on the go. Which, as it turns out, I generally don’t do.
Second question: what would I play?
There are a few titles that immediately come to mind:
- Zelda: Breath of the Wild
- Zelda: Tears of the Kingdom
- Mario Kart 8 Deluxe
- …?
When I was trying to think about the last Mario game I played, I realized that I hadn’t played one for a long time. The last Nintendo console I bought was Gamecube back in my college days, but it was primarily to play Super Smash Bros Melee and Mario Kart Double Dash. So, Super Mario… Sunshine, I never played. Nor Galaxy or Galaxy 2. Presumably they would be fun. But fun enough to justify $40 purchases of decades-old games? Ehhhh. Nintendo does have a subscription feature with classic games to play, but the Gamecube offerings right now are like 3 games (only for Switch 2).
Final question: what will I do?
After a long, exhaustive mental exercise, the answer is… Nothing. I will do nothing. I am not super convinced the OLED Switch will get any less expensive in the future, but that does not seem to matter much to me. Which makes sense, given all of my other gaming “obligations.” If anything, I would be more inclined for the Switch 2 simply because Mario Kart World does seem fun, and it’s backwards compatible, etc. Or the Retroid Pocket 5, honestly.
Or I can just continue to do waffle and whaff and do nothing until/unless some other solution releases that makes things more obviously clear. Like maybe a Steam Deck 2 or something.
More Impressions: FF7 Rebirth
I am still plugging away at Rebirth. Don’t worry, no story spoilers here.

What I did want to talk about (again) is just how baffling the game systems are. There are some things that are just awkward and annoying, but true to the original, like having to meticulously move Materia around every time your party is forced to change. Mercifully, the devs do allow you to equip Materia into a slot from someone else, eliminating some of the tedium.
But then there is all the new stuff. Which exists for… some reason, to the detriment of the game.
Weapons have Weapon Skill slots, which act like Materia (e.g. slot them), but I honestly have no clue where they come from. Maybe I missed the tutorial for that part and they automatically unlock? Anyway, they are pretty minor and largely inconsequential fiddly bits you have to mess with on occasion. Then you have the Folios, which reminds me of the Sphere Grid from Final Fantasy X. Or would if any choices there mattered either. Yes, the Folios are where you unlock Synergy Abilities and special magic attacks that don’t require MP. But along the way you have to spent points on things like “increase MP by 3” and “increase whatever by 5%.” Filler by itself is not always bad, but this is just one of a myriad of new systems introduced, again, for what reason?
And by the way, what Rebirth has done with spellcasting makes me wonder why they bothered with it at all. One of the issues of the first game (Remake) is wandering into a boss fight that hinges on you exploiting an elemental weakness that none of your team has equipped. With the Folios, all characters can unlock specific abilities that allow them to cast most elements without needing the Materia or even MP. That’s cool. However, the introduction of Synergy Abilities – which require two characters to perform ~3 ATB actions apiece – places a huge emphasis on executing actions that “count” towards them. What doesn’t count? Spells and those abilities that cast spells. Which… why not? Seriously. Combined with characters that have elemental-based ATB attacks like Cloud’s Firebrand, the whole spell system feels de-emphasized.

The other element (har har) that is becoming more annoying to me over time is the disparity between the characters themselves. Specifically, Tifa and Red XIII versus Yuffie. Both Tifa and Red XIII are melee-only characters that end up facing what feels like 80% flying enemies thus far. Not only can they not hit these flying mobs to gain ATB, many of their abilities won’t hit either. Enter Yuffie: primarily a melee character, that can also throw her Shuriken at distant/flying foes as a secondary attack. If it hits, a second tap of the button will teleport her to the Shuriken and allow her to start melee attacking the target, even in mid-air. Alternatively, if you start hitting the regular attack button, Yuffie will start attacking with her elemental ninjitsu, which is an instantaneous ranged attack. Did I mention she can change the element of the ninjitsu to target weaknesses?
I will concede that perhaps the devs feel a bit boxed in here. Tifa has the same attacks she did in the first game, as does Yuffie… who was released as a solo DLC character, and thus needed to have a broad spectrum of attacks to make up for it. At the same time, with all the craziness of Remake, I don’t think anyone would bat an eye at Tifa/Red having some way of engaging flying foes. Whatever the case, the end result is that while I want my party to be Cloud, Tifa, and Aerith, the classical trio is way outclassed by Cloud, Yuffie, and Barret. Sure, I could just do what I want and just take the OG crew, but that will make the enormously boring fights take even longer.

There are two final things I wanted to talk about, that are possibly only “me” problems. I’m very important, of course, so these are major issues. Those issues are Pacing and Tone.
From a Pacing perspective, Rebirth effectively has none. What typically happens is that you get to a new area, have a few Main Story Quests (MSQ), and then the next stage is far away into a blank map. Some of the time it is possible to make a direct approach and ignore the 20+ map icons and side quests and towers and collectibles and so on and so forth. There was even a time when the MSQ was almost directly in sight and you had to go out of your way to leave the area to hit up all the extraneous stuff. Other times you do have to unlock a certain amount of things and/or need to hit certain level milestones to not be stomped by the next boss. Regardless, I’m not a completionist or an achievement hunter, but I do actually care about extracting every drop of interaction I can from these characters that occupied so much of my youth, so I end up finishing everything I can stand.
Unfortunately, the end result is that I spend 2-3 play sessions doing busywork with this awful combat system and just can’t bring myself to push further into the story until I mentally recharge.

Double-unfortunately for me, the Tone for this game is all over the place. The original FF7 had extremely weird sections and comic relief at regular intervals, of course – the entire Wall Market sequence, for example. But I feel like the devs decided that every air pocket created from stretching the game into a trilogy needed to filled with nonsense. And not just a little nonsense, but ridiculous nonsense. Which again, fine, comic relief is a thing. However, the game isn’t that heavy to justify this amount of relief. Indeed, it’s hard to take much of anything seriously based on the in-game presentation. For example, there is a section in which Shrina soldiers are gunned down and everyone is somber and clutching pearls. Fast-forward past a bunch of filler quests (god, I wish I could have), you face off against a bunch of Shrina soldiers… that you gun down. What.
If it sounds like I’m not having a good time, you would be correct. I am currently sitting at 46 hours and sort of wish things had ended 30 hours ago. In the interest of plowing ahead, I have started to actually ignore the more Ubisoft-styled busywork, but it’s still tough.
This game is not the follow-up to Remake I was hoping for.
OldSpend vs NewSpend
A couple weeks back, the blogging theme of the week was looking at how much money you’ve spent on Steam over the years. I was not entirely interested at the time, but after navigating my way to the result, what I did find interesting were two distinct numbers:
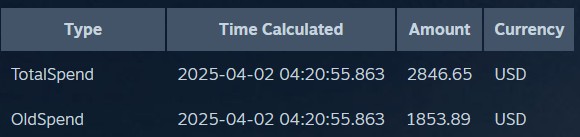
“OMG I spent $2,846.65 over the course of… like 21 years!” Sure. I don’t consider $11.30/month over more than two decades a particularly noteworthy entertainment budget. Especially considering I played WoW for more than half that time. Certainly cheaper than (now) Netflix.
No, the interesting number is the OldSpend of $1,853.89. That number (already in the total) is defined as money spent before 2015, when there was presumably some updates to the backend systems. Which means I spent 66% of the total amount on Steam games in the first 10 years as compared to the last 11. That tracks with the rise of Humble Bundles, the decline of Steam sales, and so on.
Steam is still getting their cut of sales from these middlemen, but I did find it interesting nonetheless.
/Sweat
Got this email yesterday:

____
Got this email earlier today:

So… what’s the over/under for whether the RG35XXSP will make it to my door as-is versus a letter saying it now costs $112.21? Or maybe de minimis applies and it’ll just be 30% higher… or an extra $25. Or both. Or neither.
Weeee.
Flu A
I’ve never gotten a 102+ degree fever for five days in a row before, and when your whole family gets the same thing at the same time… no bueno.
The extra dumb thing comes after you “recover”: round two secondary diseases! Laryngitis, sinus infection, whatever happens to be laying around the house, etc. We’re slowly unburying ourselves over here, but it’s going to be taking a while. Mask up, or if you have young kids, well, good luck.
